LLM 이란?
Large Language Model
대규모 언어 모델(LLM)은 텍스트 생성 및 분류, 대화형 질문에 대한 답변, 텍스트 번역 등 다양한 자연어 처리(NLP) 작업을 수행할 수 있는 일종의 머신 러닝 학습 언어 모델입니다. 여기서 '대규모'라는 뜻은 언어 모델이 상당한 양의 텍스트를 학습하면서 자율적으로 변경할 수 있는 값(매개변수)의 수를 나타냅니다.
Langchain 🦜🔗
Langchain은 언어 모델로 구동되는 애플리케이션을 개발하기 위한 프레임워크입니다. 물론OPENAI가 제공하는 API를 통해서 직접 호출을 해서 사용을 할 수 있지만 그 외 다양한 오픈소스 언어 모델들도 거의 같은 방식으로 사용할 수 있게끔 추상화를 해놓아주었고 LLM을 다룰때 필요한TextSplitter,Prompt,OutputParser같은 필요한 메소드들을 제공해줍니다. 그래서 해당 프레임워크를 사용해서 간단히 실습을 했었던 내용을 바탕으로 이론적인 부분을 적어보려고 합니다. 학습은 이 링크에서 했습니다 !
실습한 결과물의 전체적인 다이어그램
Embeddings
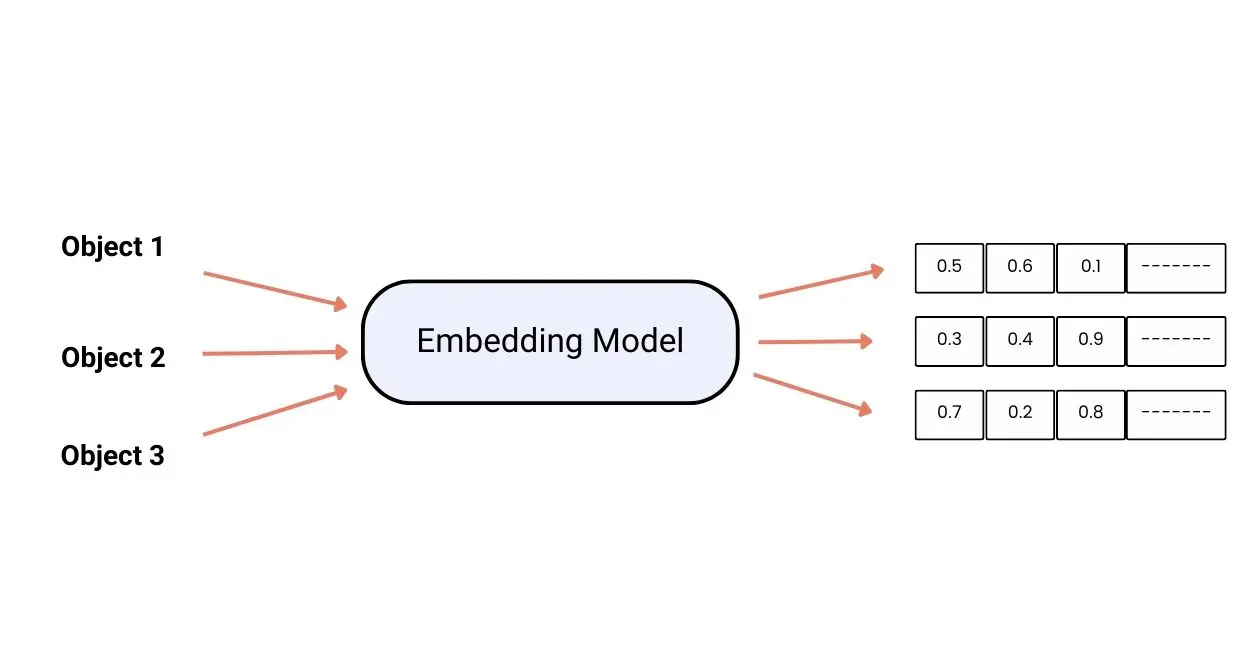
LLM 관련되어 보다보면 Embedding이라는 단어를 많이보게 됩니다. Embedding(또는 embedding vector)이란, 텍스트, 이미지, 비디오 등 정보를 실수 벡터 형태(i.e. floating point 숫자들로 구성된 고정된 크기의 배열)로 표현한 결과물을 의미합니다. 연관이 있는 단어끼리는 숫자들의 근사치에 가깝게 나오게됩니다. 이렇게 Embedding 작업을 해주는 모델 또한 여러개로 나눠져있고 구성된 알고리즘이나 학습된 방식에따라 다른 한 종류의 머신러닝 모델들이라고 할 수 있습니다. 구글 검색이나 넷플릭스 작품 추천해주는 것도 같은 원리라고 합니다.
Vector DB
실습에서는
Supabase를 사용했는데 그 외 다른 DB들도 쉽게 사용이 가능합니다.https://js.langchain.com/docs/integrations/vectorstores에서 확인할 수 있고, 다른 DB들을 살펴보지 못했지만Supabase는 공식문서에서 벡터 데이터베이스를 테이블에 만드는 SQL 쿼리를 통째로 주기때문에 처음 세팅이 간편했다. 이런식으로 데이터베이스를 사용해도 되고, 로컬로Embedding컨텍스트를 가지고 있어도 된다.
Recursively split by character
LangChain에서 지원해주는 Text Splitter의 종류는 정말 많은데 일단 저같은 경우는 일반적으로 특별하지 않은 텍스트이기 때문에
라는 메소드를 사용해서 청크로 나누었습니다. 일단 이 RecursiveCharacterTextSplitterSpliiter같은 경우는 의미적으로 가장 연관성이 강한 텍스트 조각인 것처럼 보이는 모든 단락을 문자목록을 매개변수화해서 저장하고, 가능한 길게 유지하려�는 효과가 있습니다.
const textSplitter = new RecursiveCharacterTextSplitter({
// 분할할 청크의 사이즈
chunkSize,
// 청크간 겹치는 것을 허용할 사이즈
chunkOverlap,
// separators들을 기준으로나눠줍니다.
separators: ["\n\n", "\n", ". ", "? ", "! ", ".\n", "?\n", "!\n"],
});
TextSplitter를 사용하는 이유는 뭘까 ?
임베딩 모델에 따라 최대 토큰 한도가 있습니다. 보통 텍스트 데이터의 양들은 대부분 그 한도 토큰을 넘기기 때문에 이렇게 TextSplitter를 통해서 나눠줘야합니다.
Store Embeddings in Vector DB
위에 3가지 요소를 알면 이제 Vector 데이터 베이스에 나의 텍스트 데이터를 저장할 수 있습니다. 저의 코드를 간단히 설명해보겠습니다. 저는 빌드타임에 아래와 같이 아래 스크립트 코드를 실행하게 만들었습니다. 더 추상화를 할 수 있지만 흐름대로 볼 수 있을것 같아 아래와 같이 작성해봤습니다.
const filePath = "텍스트파일 경로";
export const run = async () => {
try {
// 파일경로에 있는 텍스트 데이터를 가져와줍니다.
const loader = new TextLoader(filePath);
const rawDocs = await loader.load();
// textSplitter에 청크사��이즈, 오버랩 등 옵션을 추가해서 클래스를 생성해줍니다.
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 200,
separators: ["\n\n", "\n", ". ", "? ", "! ", ".\n", "?\n", "!\n"],
});
// 텍스트 데이터를 주어진 옵션대로 쪼개어 줍니다.
const docs = await textSplitter.splitDocuments(rawDocs);
console.log("🔍 Checking environment variables\n");
// 필요한 환경변수를 불러와주고, supabase 클라이언트 인스턴스도 생성해줍니다.
const supabase_api_key = process.env.SUPABASE_API_KEY;
const sbUrl = process.env.SUPABASE_URL;
const openAIApiKey = process.env.OPENAI_API_KEY;
const client = createClient(sbUrl as string, supabase_api_key as string);
console.log("🔗 Connecting to Supabase\n");
// 현재 데이터베이스에 저장되어 있는 데이터가 있는지 확인합니다.
let { data: existingData, error } = await client
.from("documents")
.select("*")
.limit(1);
if (error) {
throw Error("Error fetching data from Supabase:");
}
// 이미 존재하는 데이터가 있다면, 임베딩을 다시 할 필요가 없으니까 함수를 종료해줍니다.
if (existingData && existingData.length > 0) {
console.log("📚 Data already exists in Supabase, skipping process.\n");
return;
}
// OPENAI 임베딩 모델을 이용해서 바로 Supabase 데이터베이스에 주입해줍니다.
await SupabaseVectorStore.fromDocuments(
docs,
new OpenAIEmbeddings({ openAIApiKey }),
{
client,
tableName: "documents",
}
);
console.log("🎉 Vector data created in Supabase\n");
} catch (error) {
console.log("❌ Error", error);
throw new Error("Failed to ingest your data");
}
};
(async () => {
await run();
console.log("✅ Ingestion complete\n");
})();
Standalone Question
유저의 인풋을 받아서 해당 텍스트를 통해서 비슷한 좌표에 있는 벡터를 찾아야하는데, 짧은 단어 검색이면 상관없겠지만 컨텍스트가 길어지면 토큰도 커질뿐더러 검색 결과에도 악영향을 끼치게 됩니다. 그래서 유저의 인풋 그대로 검색을 하면 좋지 않고,
Standalone Question 으로 가공해서 해주게 됩니다.
Retriever
Retriever 는 비정형 쿼리에 대한 응답으로 문서를 반환하는 인터페이스입니다. 즉 이 인터페이스를 통해서 우리가 데이터베이스에 저장했던 임베딩에서Standalone Question 과 제일 근사치에 가까운 벡터 데이터를 찾게 됩니다. 저는 아래와 같이 함수로 따로 빼서 해당 추출을 해주었습니다.
export const getRemoteRetriver = async (): Promise<
VectorStoreRetriever<SupabaseVectorStore>
> => {
console.log("Loading existing remote vector store...");
const vectorStore = new SupabaseVectorStore(embeddings, {
// Supabase 인스턴스
client,
// Supabase 테이블 이름
tableName: "documents",
// Supabase 사용할 쿼리 이름
queryName: "match_documents",
});
console.log("Vector store loaded.");
return vectorStore.asRetriever();
};
Chain
Chaining은 LLM, tool 혹은 데이터 전처리 단계등을 일련의 호출로 나타내어 줍니다. 가장 기본적으로 사용되는 유즈케이스는 아래와 같이
prompt + model + output parser 일련의 체인을 만들어 주는 것입니다.Langchain에서는LCEL을 통해서 Chaining을 지원합니다.
// 독립적 질문 생성
const standaloneQuestionChain = createStandaloneQuestionChain(llm);
function createStandaloneQuestionChain(llm: ChatOpenAI) {
// Standalone 프롬프트 생성
const standaloneQuestionPrompt = PromptTemplate.fromTemplate(
standaloneQuestionTemplate
);
//
return standaloneQuestionPrompt.pipe(llm).pipe(new StringOutputParser());
}
LCEL은 뭘까요?
LCEL는LangChain Expression Language 의 약자입니다. 가장 단순한 체인부터 가장 복잡한 체인까지 코드 변경 없이 체인을 쉽게 구성하는 선언적 방법입니다.. 아래pipe()도 LCEL에 하나라고 합니다.
return standaloneQuestionPrompt.pipe(llm).pipe(new StringOutputParser());
자세한 이점과 특징은 링크에서 확인해주세요.
Get Response from Embedding Data
위 내용을 토대로 아까 위에서 저장했던 벡터데이터들을 기반으로 입력에 대한 대답을 하는 코드인데, Nextjs 프레임워크 api 라우트에서 작성된 Node 코드인데 주석을 통해 설명을 해보겠습니다.
export default async function handler(
req: NextApiRequest,
res: NextApiResponse
) {
// 입력으로 그간 대화 히스토리와 질문을 가져옵니다.
const { conversation_history, question } = req.body;
// 필요한 환경변수와 LLM
const openAIApiKey = process.env.OPENAI_API_KEY;
const llm = new ChatOpenAI({ openAIApiKey });
const VECTOR_STORE_PATH = "store";
let retriever: VectorStoreRetriever;
console.log("🔍 Checking for existing vector store...");
// 로컬에 벡터 스토어가 존재하는지 확인합니다.
// 로컬에 존재하면 로컬 리트리버를, 그렇지 않으면 원격 리트리버를 사용합니다.
if (fs.existsSync(VECTOR_STORE_PATH)) {
console.log("📚 Vector store found, using local retriever...");
retriever = await getLocalRetriever();
} else {
console.log("🌐 Vector store not found, using remote retriever...");
retriever = await getRemoteRetriver();
}
// 독립적 질문 생성
// 리트리버 체인 생성
// 답변 체인 생성
// 함수들은 아래에 모아 놨습니다.
const standaloneQuestionChain = createStandaloneQuestionChain(llm);
const retrieverChain = createRetrieverChain(retriever);
const answerChain = createAnswerChain(llm);
console.log("🔗 Building the runnable sequence chain...");
// LCEL를 통해 Chain들을 이어줍니다.
const chain = RunnableSequence.from([
{
standalone_question: standaloneQuestionChain,
original_input: new RunnablePassthrough(),
},
{
context: retrieverChain,
question: ({ original_input }) => original_input.question,
conversation_history: ({ original_input }) =>
original_input.conversation_history,
},
answerChain,
]);
console.log("🚀 Invoking the runnable sequence chain...");
// 체인을 실행합니다.
const response = await chain.invoke({
question,
conversation_history,
});
console.log("✅ Runnable sequence chain invoked successfully!");
res.status(200).json({ response });
}
// LCEL을 통해서 각 체인들을 만들어주는 함수를 따로 추출해주었습니다.
function createStandaloneQuestionChain(llm: ChatOpenAI) {
const standaloneQuestionPrompt = PromptTemplate.fromTemplate(
standaloneQuestionTemplate
);
return standaloneQuestionPrompt.pipe(llm).pipe(new StringOutputParser());
}
function createRetrieverChain(retriever: VectorStoreRetriever) {
return RunnableSequence.from([
prevResult => prevResult.standalone_question,
retriever,
combineDocuments,
]);
}
function createAnswerChain(llm: ChatOpenAI) {
const answerPrompt = PromptTemplate.fromTemplate(answerTemplate);
return answerPrompt.pipe(llm).pipe(new StringOutputParser());
}
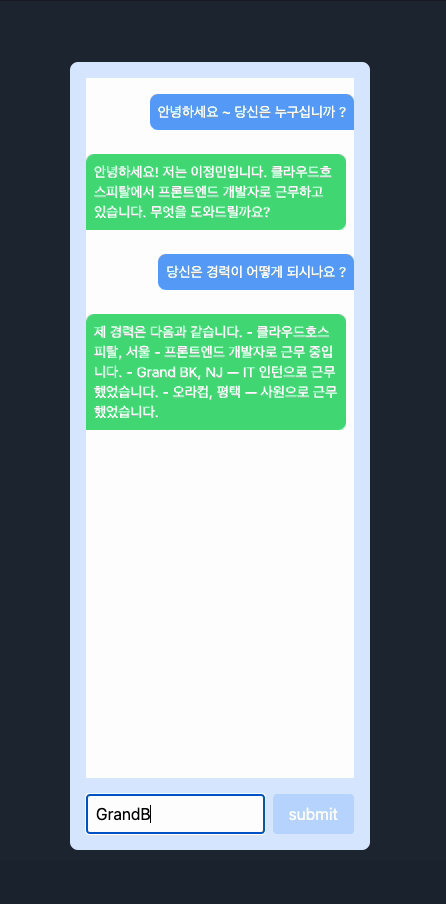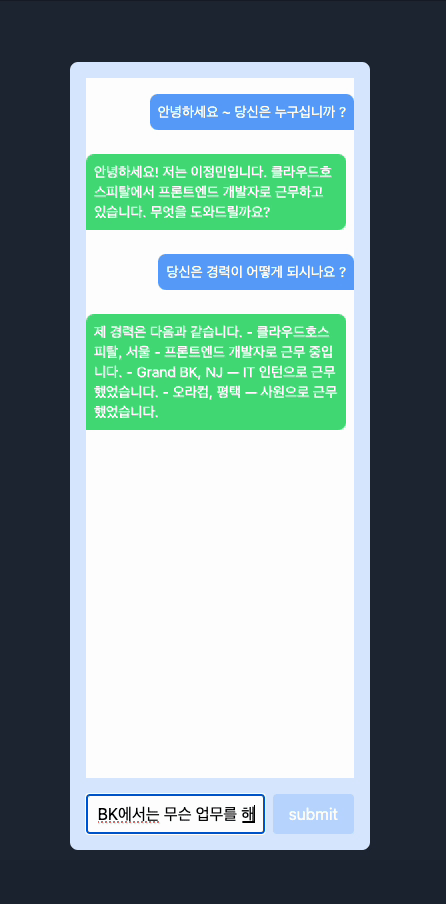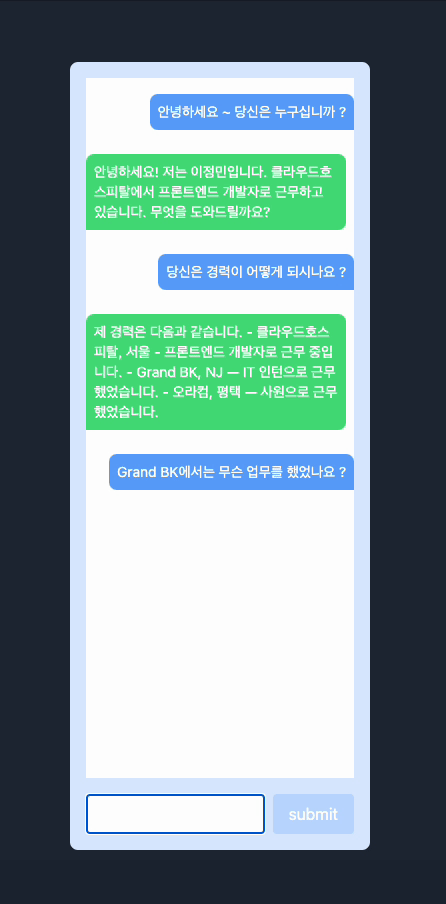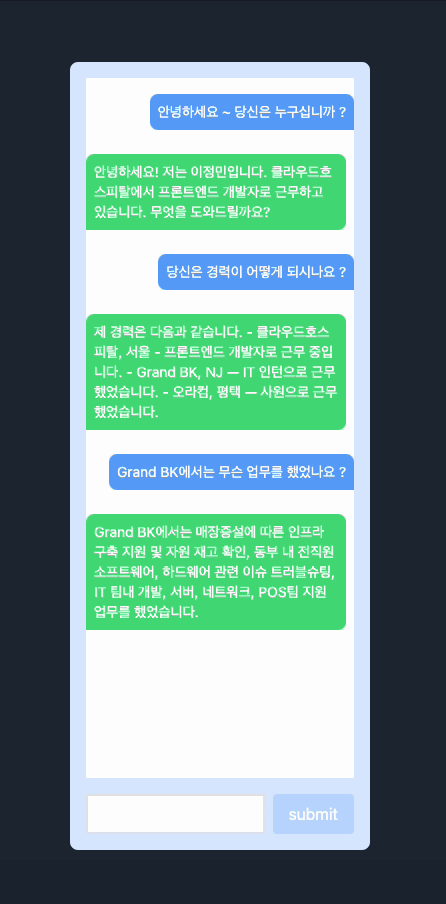
Demostration
제일 간단하게 제 이력서와 간략한 정보를 입력하고 저장해서 저에 대해서 물어보았고, 기본적으로 프로프팅이 정리가 안되어있어서 어색한 부분은 있었지만 나름대로 괜찮은 것 같습니다. 이 경험을 바탕으로 한번 포트폴리오랑 자그마한 사이드 프로젝트를 진행해보려고 합니다.